

A data warehouse is a data management system that stores current and historical data from multiple sources in a business friendly manner for easier insights and reporting. Data warehouses are typically used for business intelligence (BI), reporting and data analysis.
Data warehouses make it possible to quickly and easily analyze business data uploaded from operational systems such as point-of-sale systems, inventory management systems, or marketing or sales databases. Data may pass through an operational data store and require data cleansing to ensure data quality before it can be used in the data warehouse for reporting.
Here’s more to explore
Your next data warehouse?
Run all data workloads on one platform.
Download now
Big Book of Data Warehousing and BI
Your complete how-to guide to data warehousing with the Data Intelligence Platform — including real-world use cases.
Big Book of Data Engineering
Fast-track your expertise with this essential guide for the AI era.
Data warehouses are used in BI, reporting, and data analysis to extract and summarize data from operational databases. Information that is difficult to obtain directly from transactional databases can be obtained via data warehouses. For example, management wants to know the total revenues generated by each salesperson on a monthly basis for each product category. Transactional databases may not capture this data, but the data warehouse does.
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two different ways of transforming data. Data engineers often use ETL, or extract-transform-load, to extract data from different data sources and move it into the data warehouse, where they can easily cleanse and structure it. ELT, on the other hand, loads data into the warehouse in its original format first, and cleanses and structures it as it is processed.
ETL is typically done more centrally via Enterprise Data Engineering teams to apply company-wide data cleansing and conforming rules. ELT implies transformations are done at a later stage which are typically more project/business team specific - to enable self-service analytics.
An Online Transaction Processing (OLTP) system captures and maintains transactional data in a database. Transactions involve individual database records made up of multiple fields or columns. OLTP databases are commonly used in applications like online banking, ERP systems, or inventory management, enabling quick updates to row-level data that are processed nearly instantly.
An Online Analytical Processing (OLAP) system applies complex queries to large amounts of historical data, aggregated from OLTP databases and other sources, for data mining, analytics, and business intelligence projects. Data warehouses are OLAP systems. OLAP databases and data warehouses give analysts and decision-makers the ability to use custom reporting tools to turn data into information and action. Query failure on an OLAP database does not interrupt or delay transaction processing for customers, but it can delay or impact the accuracy of business intelligence insights.
A data lake and a data warehouse are two different approaches to managing and storing data.
A data lake is an unstructured or semi-structured data repository that allows for the storage of vast amounts of raw data in its original format. Data lakes are designed to ingest and store all types of data — structured, semi-structured or unstructured — without any predefined schema. Data is often stored in its native format and is not cleansed, transformed or integrated, making it easier to store and access large amounts of data.
A data warehouse, on the other hand, is a structured repository that stores data from various sources in a well-organized manner, with the aim of providing a single source of truth for business intelligence and analytics. Data is cleansed, transformed and integrated into a schema that is optimized for querying and analysis.
A data lakehouse is a hybrid approach that combines the best of both worlds. It is a modern data architecture that integrates the capabilities of a data warehouse and a data lake in a unified platform. It allows for the storage of raw data in its original format like a data lake while also providing data processing and analytics capabilities like a data warehouse.
In summary, the main difference between a data lake, a data warehouse and a data lakehouse is their approach to managing and storing data. A data warehouse stores structured data in a predefined schema, a data lake stores raw data in its original format, and a data lakehouse is a hybrid approach that combines the capabilities of both.
All types: Structured data, semi-structured data, unstructured (raw) data
All types: Structured data, semi-structured data, unstructured (raw) data
Structured data only
Closed, proprietary format
Scales to hold any amount of data at low cost, regardless of type
Scales to hold any amount of data at low cost, regardless of type
Scaling up becomes exponentially more expensive due to vendor costs
Limited: Data scientists
Unified: Data analysts, data scientists, machine learning engineers
Limited: Data analysts
Low quality, data swamp
High quality, reliable data
High quality, reliable data
Difficult: Exploring large amounts of raw data can be difficult without tools to organize and catalog the data
Simple: Provides simplicity and structure of a data warehouse with the broader use cases of a data lake
Simple: Structure of a data warehouse enables users to quickly and easily access data for reporting and analytics
A data lake and a data warehouse are two different approaches to managing and storing data, each with its own strengths and weaknesses. While a data lake can complement a data warehouse by providing raw data for advanced analytics, it cannot in its traditional sense fully replace a data warehouse. Instead, a data lake and a data warehouse can complement each other, with the data lake serving as a source of raw data for advanced analytics, and the data warehouse providing a structured, organized and trustworthy source of business data for reporting and analysis.
A data lakehouse, however, is a modern data architecture that combines the benefits of a data warehouse and a data lake into a unified platform. A data lakehouse can serve as a replacement for a traditional data warehouse because it provides the capabilities of both a data lake and a data warehouse in a single platform.
A data lakehouse allows for the storage of raw data in its original format like a data lake while also providing data processing and analytics capabilities like a data warehouse. It also provides a schema-on-read approach, which allows for flexibility in data processing and querying. The combination of a data lake and a data warehouse in a single platform provides increased flexibility, scalability and cost-effectiveness.
A database is a structured repository that stores data in a predefined schema, optimized for transactional processing and business applications. Databases are designed to handle structured data and provide fast, efficient and reliable querying and data processing capabilities. They use a schema-on-write approach, which means that data must be structured and defined before it can be stored in the database. Databases are often used in applications such as e-commerce, banking, and inventory management, where transactional processing is critical for business operations.
A data lake is an unstructured or semi-structured data repository designed to ingest and store all types of data in its original format — structured, semi-structured or unstructured — without any predefined schema. The data stored in its native format is often not cleansed, transformed or integrated, making it easier to store and access large amounts of data. Data lakes are often used for advanced analytics and machine learning applications, where data exploration and discovery are critical for gaining insights and building predictive models.
A data lake and ETL (extract, transform, load) are two different concepts related to data management and integration. The main difference is that a data lake is a centralized repository for storing and processing vast amounts of raw data, while ETL is a process for extracting, transforming and loading structured data from multiple sources into a target data repository. A data lake allows for the storage and processing of all types of data, without any predefined schema, while ETL is typically used for integrating structured data into a predefined schema.
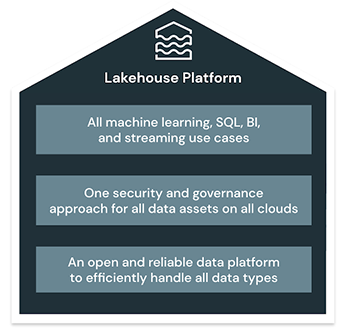
Lakehouse architectures specifically solve these challenges in order to offer the best of both data lakes and warehouses. See the value of an open lakehouse architecture on Databricks.
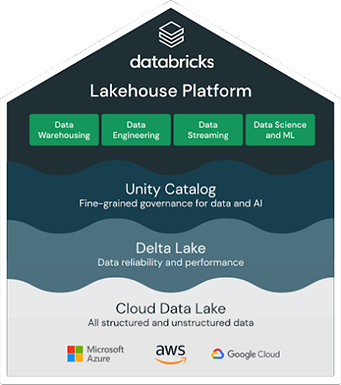
To build a successful lakehouse, organizations have turned to Delta Lake, an open source, open format data management and governance layer that combines the best of both data lakes and data warehouses. The Databricks Lakehouse Platform uses Delta Lake to give you: